Deep representation features from DreamDIAXMBD improve the analysis of data-independent acquisition proteomics
Abstract
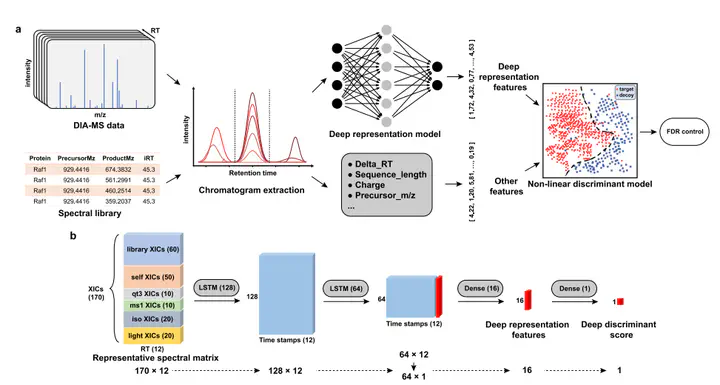
We developed DreamDIAXMBD (denoted as DreamDIA), a software suite based on a deep representation model for data-independent acquisition (DIA) data analysis. DreamDIA adopts a data-driven strategy to capture comprehensive information from elution patterns of peptides in DIA data and achieves considerable improvements on both identification and quantification performance compared with other state-of-the-art methods such as OpenSWATH, Skyline and DIA-NN. Specifically, in contrast to existing methods which use only 6 to 10 selected fragment ions from spectral libraries,DreamDIA extracts additional features from hundreds of theoretical elution profiles originated from different ions of each precursor using a deep representation network.To achieve higher coverage of target peptides without sacrificing specificity, the extracted features are further processed by nonlinear discriminative models under the framework of positive-unlabeled learning with decoy peptides as affirmative negative controls. DreamDIA is publicly available at https://github.com/xmuyulab/DreamDIA-XMBD for high coverage and accuracy DIA data analysis.