Abstract
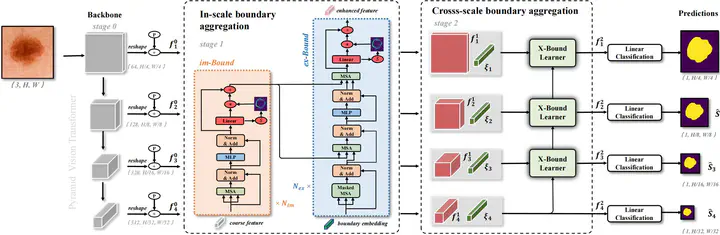
Skin lesion segmentation from dermoscopy images is of great significance in the quantitative analysis of skin cancers, which is yet challenging even for der matologists due to the inherent issues, i.e., considerable size, shape and color variation, and ambiguous bound aries. Recent vision transformers have shown promising performance in handling the variation through global con text modeling. Still, they have not thoroughly solved the problem of ambiguous boundaries as they ignore the com plementary usage of the boundary knowledge and global contexts. In this paper, we propose a novel cross-scale boundary-aware transformer, XBound-Former, to simulta neously address the variation and boundary problems of skin lesion segmentation. XBound-Former is a purely attention-based network and catches boundary knowledge via three specially designed learners. First, we propose an implicit boundary learner (im-Bound) to constrain the network attention on the points with noticeable bound ary variation, enhancing the local context modeling while maintaining the global context. Second, we propose an ex plicit boundary learner (ex-Bound) to extract the boundary knowledge at multiple scales and convert it into embed dings explicitly. Third, based on the learned multi-scale boundary embeddings, we propose a cross-scale bound ary learner (X-Bound) to simultaneously address the prob lem of ambiguous and multi-scale boundaries by using learned boundary embedding from one scale to guide the boundary-aware attention on the other scales. We evaluate the model on two skin lesion datasets and one polyp lesion dataset, where our model consistently outperforms other convolution- and transformer-based models, especially on the boundary-wise metrics.